Using DQR: Bulk Querying and Importing via CSV File
Let's say that you already have a list of the studies you want to import and don't want to have to individually search for each of them. In cases like these, the Import CSV option can be very helpful.
Like with a normal import, you start by going to a project that you want to import PACS data into and then clicking "Import from PACS" in the Actions box. After you have made sure the correct "Source PACS" is selected in the dropdown, simply click the "Import CSV" link. The modal shown below will then come up:
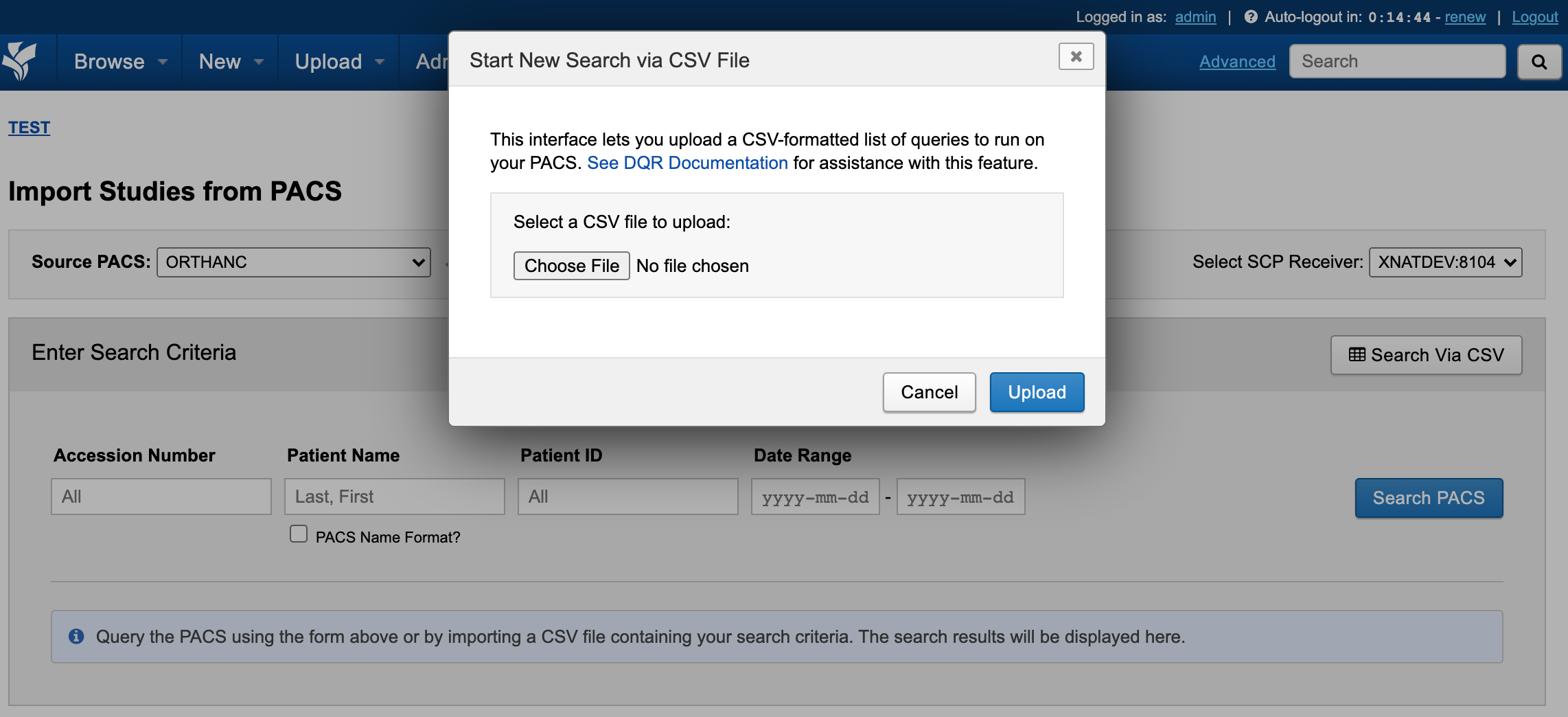
At this point, you can upload a CSV file that contains a list of queries for sessions on the remote PACS system. There are many ways you can structure these queries in the CSV file. Read below for instructions on writing and formatting these files.
Writing a CSV for DQR Import
The CSV file that you upload must contain a header row that defines which search terms and remapping fields you want to use, and one or more rows that contain search criteria. Here is a simple example:
example.csv
Accession Number,Subject,Session
25175352,Subj001,Subj001_MR1This file will send a query to the PACS for any image session with the Accession Number "25175352", and it will apply Subject and Session relabeling to that session.
CSV Search Headers
The CSV header row must contain at least one of these search headers.
These search headers must be spelled exactly as they are labeled in this table. You only need to include the search headers that you intend to use, and they can be placed in any order you wish.
CSV Header | DICOM Field to Query | Format | Notes |
|---|---|---|---|
Accession Number | Accession Number (0008,0050) | String | |
Study Date | Study Date (0008,0020) | YYYYMMDD | The search query can include a date range, i.e. |
Patient ID | Patient ID (0010,0020) | String | |
Patient Name | Patient Name (0010,0010) | LASTNAME^FIRSTNAME |
Not directly supported in CSV searches. You can submit two fields “Last Name” and “First Name”, but these may not work predictably unless you have high confidence that your list of names are representative of data in the PACS. I.e., the following is a valid CSV name search file:
CODE
However, the handling of complex names like those on lines 3–5 will depend on the specific behavior of your PACS, and may not deliver accurate results. |
DOB | Patient's Birth Date (0010,0030) | YYYYMMDD | The search query can include a date range, i.e. |
Modality | Modality (0008,0060) | String | |
Study Instance UID | Study Instance UID (0020,000D) | String (UID) | Remapping of Study Instance UID is not supported. |
CSV Remapping Headers
Optionally, you can include relabeling or remapping instructions in your CSV query document. These are not required, and many are not fully supported by UI-based imports (yet). Using these fields will modify the DICOM itself on import.
These remapping headers must be spelled exactly as they are labeled in this table. You only need to include the search headers that you intend to use, and they can be placed in any order you wish.
CSV Header | Function | Format | Notes |
|---|---|---|---|
Subject | Relabels the Patient Name DICOM field (0010,0010) to the value of your "Subject" label | String | |
Session | Relabels the following DICOM fields to the value of your "Session" label:
| String |
Entering Search Criteria in CSV Rows
Each row in your CSV file, after the header row, must contain at least one search criteria, and can contain as many remapping criteria as you like. Some basic tips:
If you have multiple search criteria, these are combined as an "AND" search. I.e., "Return all values where condition 1 AND condition 2 are true"
You may leave search criteria blank, but each row in your CSV must have at least one search criteria specified
Searches from each row in your CSV can return one, many, or no results. Any relabeling that you enter for a query is applied to all results from that query
Search results from all your queries are combined into a single results table
Let's say that I want to import a single study whose Accession Number I know, 25175352, and have that study appear in XNAT as a session under a subject named "Subj001". To do this, I could upload the following file: import-example1.csv
import-example1.csv
Accession Number,Subject
25175352,Subj001After uploading that CSV, the import page looks like this:
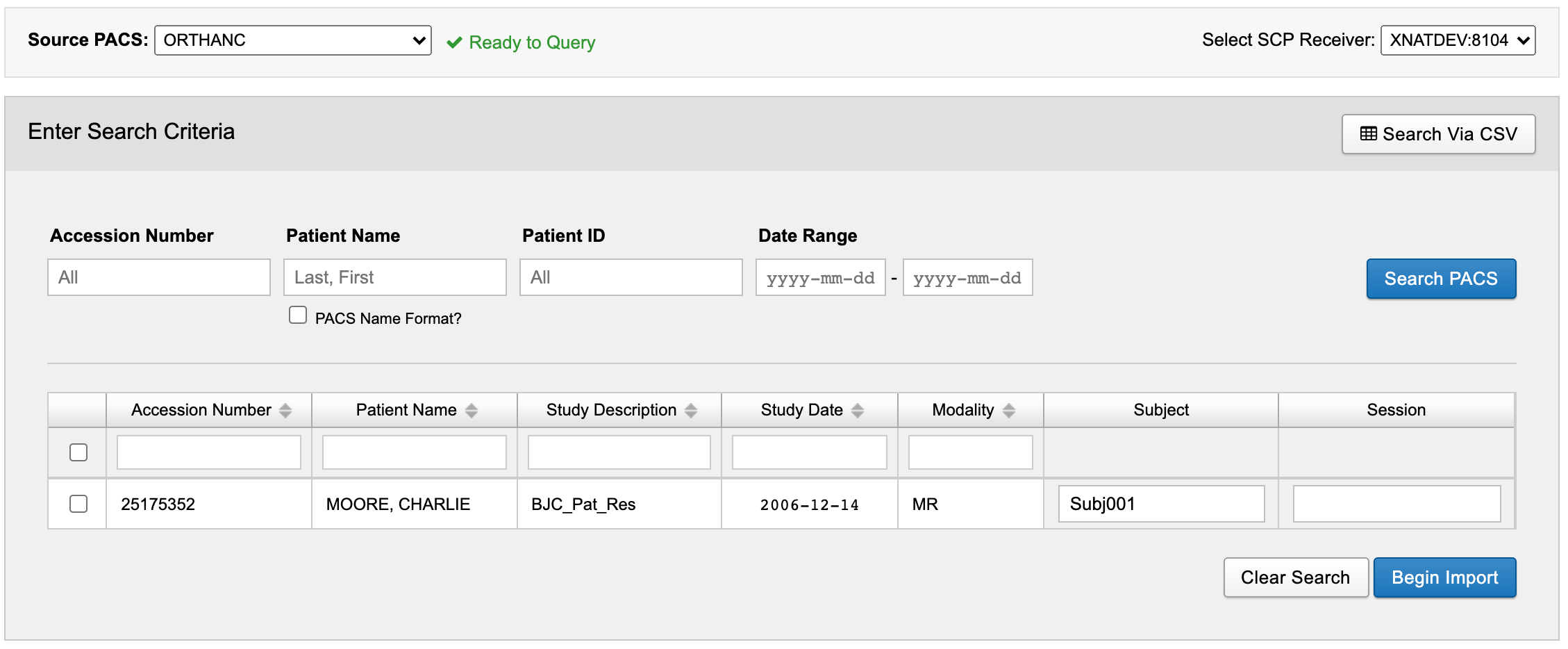
If I then check the box for this study and begin the import (leaving all series descriptions selected in the next modal), that study will be imported into XNAT. The same rules as in the earlier relabeling section still apply:
Patient's Name = value entered for Subject
Patient ID = value entered for Subject
Study ID = value entered for Session
Accession Number = value entered for Session
When the study's DICOM files are received by XNAT, the Patient's Name and Patient ID values in the DICOM are changed to "Subj001", leading to it showing up in the prearchive with Subject listed as Subj001. No session relabeling was requested, so the normal dqrObjectIdentifier rules are followed (as described in the DICOM Object Identifiers section), which means that whatever the Study ID was in the DICOM is what will be used for the session label.
Practical Limits of CSV Querying: A CSV file can contain any number of rows, where each row is a new query. However, XNAT does not have a good way to throttle its requests to a PACS system when requesting scan info for all of the selected image sessions. This can cause timeout errors when trying to request even as many as 20 sessions simultaneously. We recommend staging your CSV queries into small batches to optimize performance.
XNAT does not have the same practical limit to the number of DQR requests it can maintain in its queue.
Each line can also match as many studies in the PACS as you want. However, you should be particularly careful about the possibility that one CSV row will return multiple studies from the PACS when relabeling.
For example, a simple search on Modality is all but guaranteed to return multiple results: import-modality.csv
import-modality.csv
Modality,Subject,Session
PT,Subj002,Subj002_PTWhen attempting to apply relabeling in a situation like this, you are not likely to get the outcome you desire.
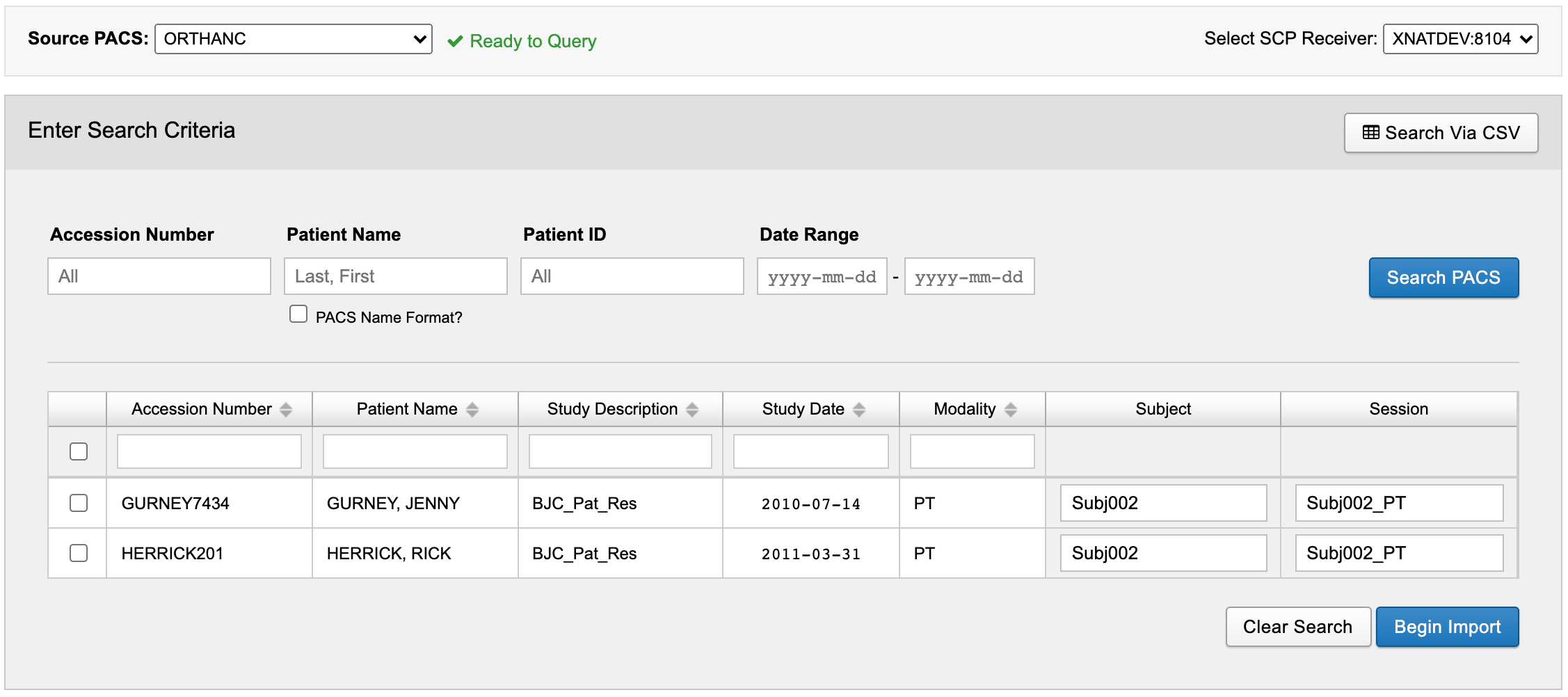
Because the CSV is only used for initial querying, you can cherry pick the results that you want to import, and/or you can modify the relabeling values for subject and session in the UI before proceeding. Or, you can re-upload a more specific CSV search. For example, the following CSV file using a combination of multiple search criteria would return a single result: import-modality-and-date.csv
import-modality-and-date.csv
Modality,Study Date,Subject,Session
PT,20110331,Subj002,Subj002_PTDetails on Allowable Search Criteria Values in the CSV
Formatting search criteria in a CSV requires some slightly different treatment than via the UI, and also allows for advanced search techniques.
Date Formats
As specified above, CSV searches on dates must be formatted as a PACS date string, i.e. "YYYYMMDD" with no spaces or punctuation in between.
Study Date
20210331Date Ranges
To specify a date range, include a hyphen between two PACS-formatted date strings, i.e. "YYYYMMDD-YYYYMMDD". (You can specify an open-ended date search by leaving off one date in the range.)
Study Date
20210301-20210331Wildcard Searches
DICOM searches use an asterisk (*) to allow for partial matches of search strings. The wildcard character can be placed anywhere in a search string and can stand for any number of missing characters. For example, each of the following would be a valid name search:
Patient Name
LASTNAME*
*FIRSTNAME
L*NAMEWildcards cannot be used with date strings
Searching for Multiple Possible Values
Different from a wildcard search, you may want to search for multiple discrete values. For this purpose, you can use the backslash (\) character.
Accession Number
25175352\8701449723783444Backslash characters cannot be used with date strings
Completing the CSV Import Process
Once you have your CSV returning the rows you want, you simply proceed like for any other import. The next steps are as follows:
Check the box for the rows that have the studies you want to import.
Make sure the Subject/Session relabeling is set up the way you want it.
Click the "Begin Import" button.
Select the series descriptions you want to import.
Click the "Import Selected" button.