Container Service
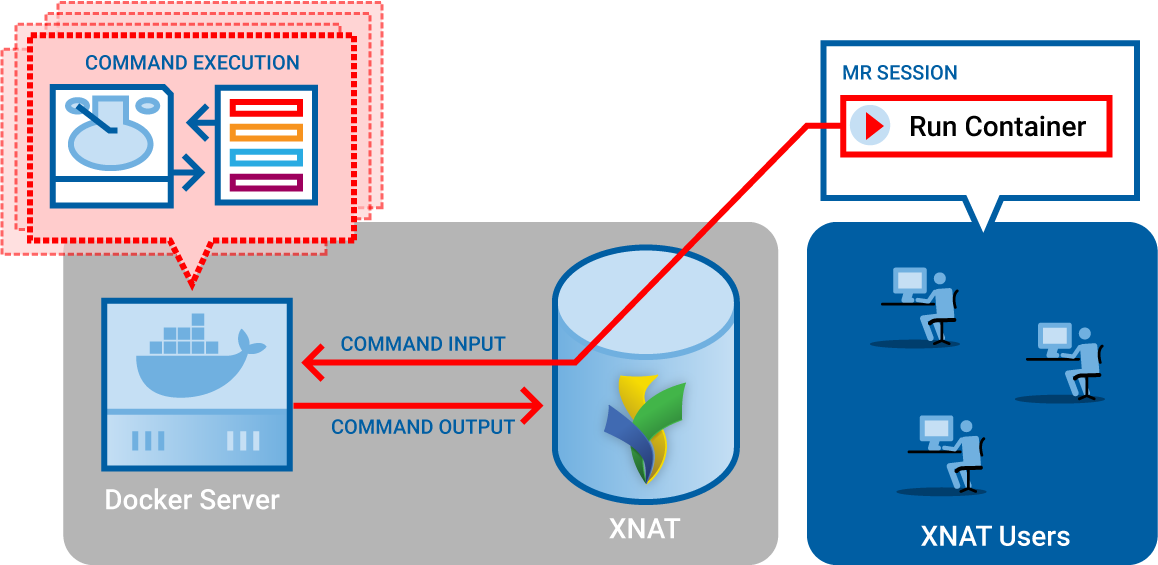

Using The Container Service
Documentation for XNAT users: how to set up and run containers on your XNAT project data.


Building Docker Images for Container Service
Everything you need to develop new images and XNAT-aware commands to integrate with the Container Service.