Defining Parameters for your Dataset
Dataset definitions define one or more criteria that can be used to locate resources within an XNAT project. (Eventually we'd like datasets to work across projects on a system and even across multiple federated XNATs, but for now they're limited to working within a single project due to XNAT's expectations about where experiments live.)
They can be thought of as stored searches or queries, defining the parameters of what should be in a data collection but not identifying any particular files or resources.
Dataset collections are what you get when a definition is resolved. Collections provide actual lists and groups of files that can be used by processing workflows.
From an overhead view, working with dataset definitions and collections is fairly simple:
- Create a dataset definition
- Validate the data in your project compared to the dataset definition
- Resolve your data with the definition to create a saved dataset
Creating a TaggedResourceMap Dataset Definition for Machine Learning
A dataset definition consists of the following primary attributes:
- Project
- ID
- Label
- Criteria, which is a collection of criterion objects, each of which consists of the ID for a criterion resolver and a payload
The dataset definition framework is flexible and extensible, so the complexity of a dataset definition depends on the type of criteria specified in the definition. For the purposes of creating a Machine Learning dataset, we will use a TaggedResourceMap resolver. This resolver takes a series of query statements and examines scan resources for individual files that match those queries.
Using the XNAT Dataset Dashboard
From your project's report page, click on the Machine Learning tab and then click on "Manage Datasets". You'll be taken to the Dataset Dashboard. The page will automatically load showing your currently saved definitions and the validation panel by default.
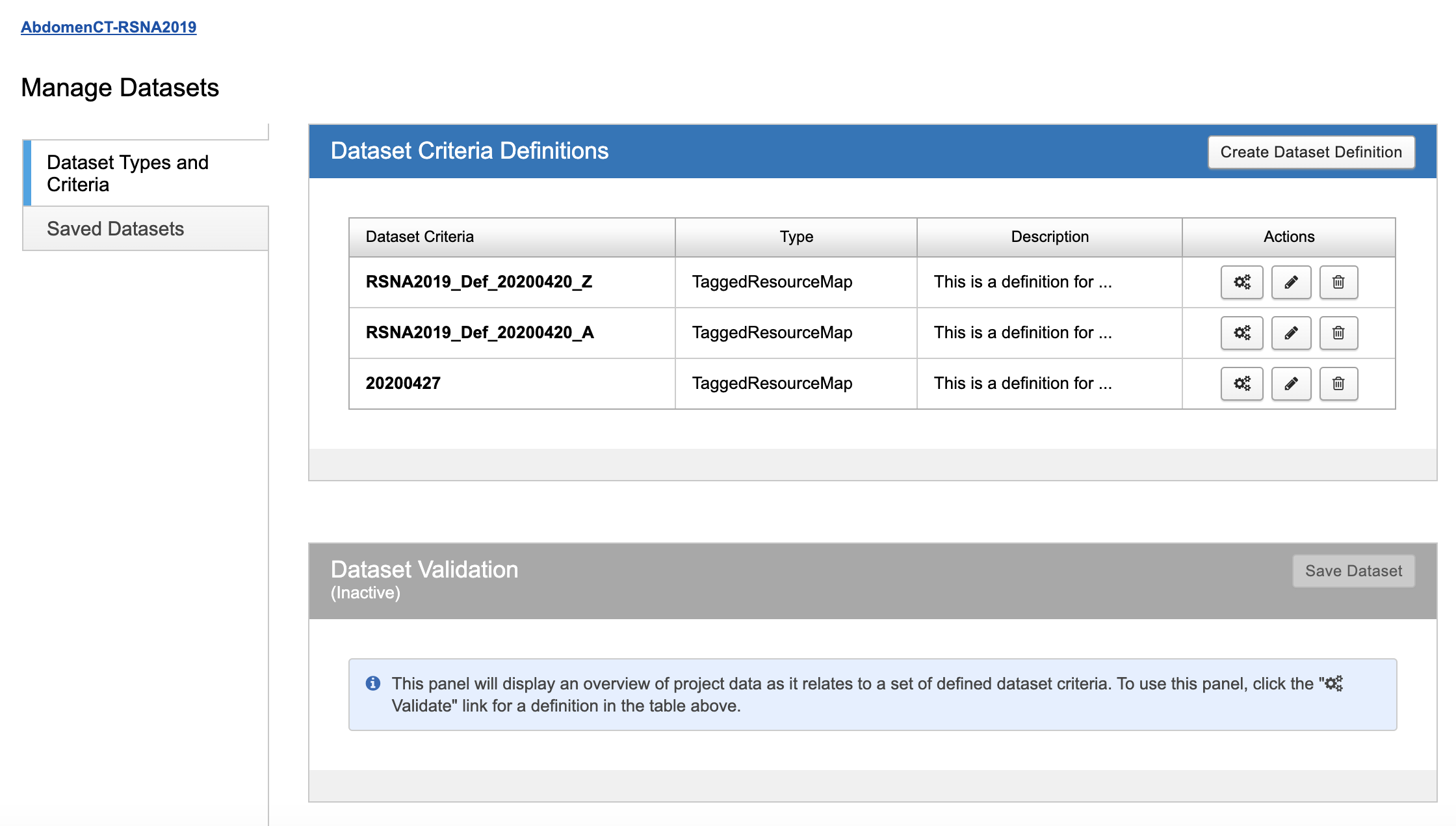
- Click "Create Dataset Definition" to open the definition dialog.
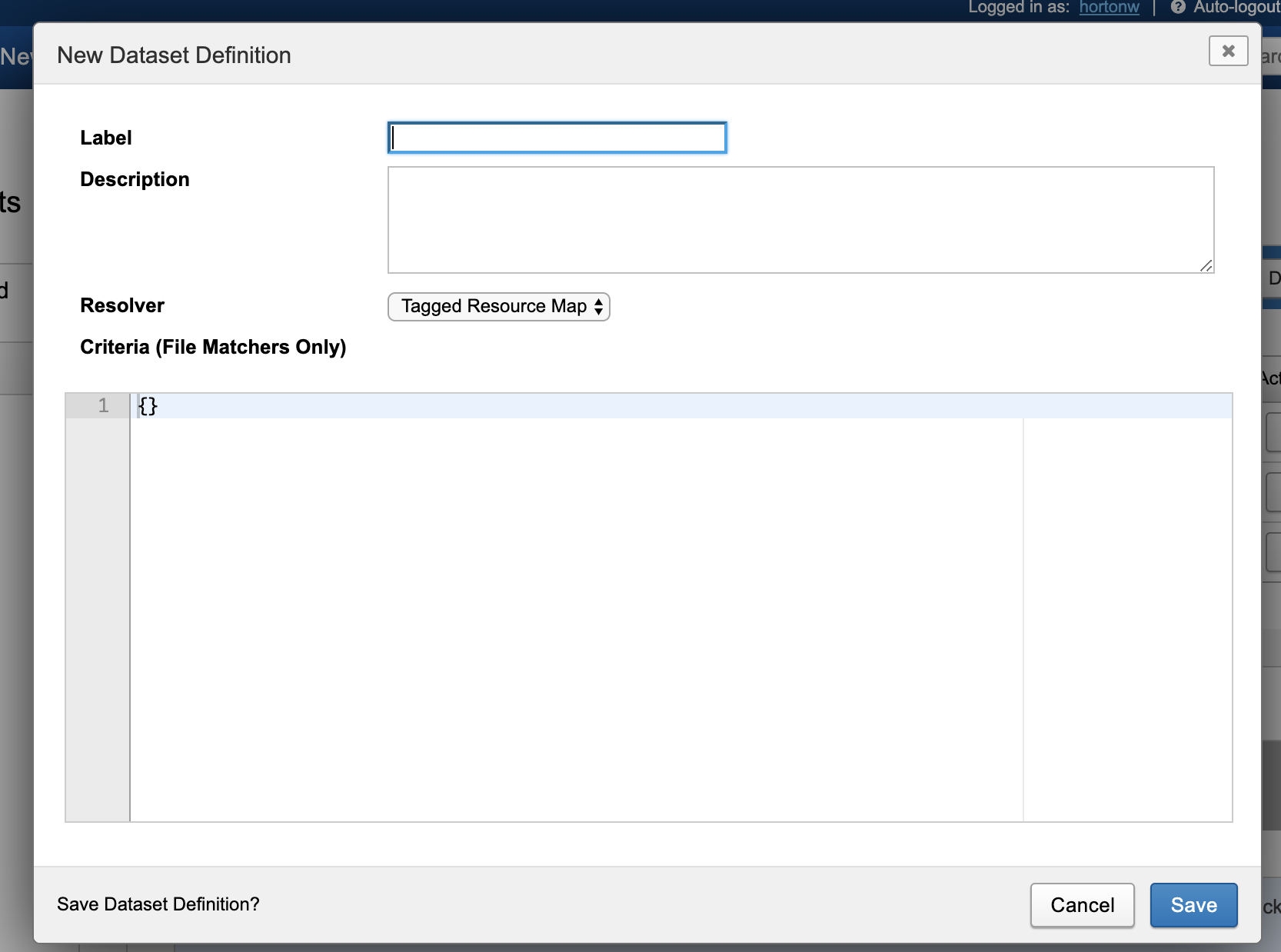
- Enter a name and description for this definition, then click into the code editor to enter your Dataset Definition Criteria. This is a set of JSON code that defines the queries you want to use to generate a list of files.
Defining a Set of Criteria
Here is an example set of criteria using the TaggedResourceMap resolver. It defines two classes of scan resource files to find, one named "image" and one named "label". In plain english, here is what this criteria is looking for:
For my "image" file(s), find all scans with a series description STARTING WITH "T1", with a resource format EQUAL TO "NIFTI", where that resource content has a label that CONTAINS "T1", and the resource format can be "NIFTI" or "nifti". Give me all resource files that match ALL of those criteria.
For my "label" file(s), find all scans with a series description STARTING WITH "Segment", with a resource format EQUAL TO "NIFTI", where that resource content has a label that MATCHES THE CASE INSENSITIVE REGEX PATTERN "Segment.{3}", and the resource format can be "NIFTI" or "nifti". Give me all resource files that match ALL of those criteria.
Dataset Definition Criteria Payload
{
"Images": {
"tag": "image",
"SeriesDescription": [
"T1%"
],
"ResourceFormat": [
"NIFTI"
],
"ResourceContent": [
"/T1./i"
],
"ResourceLabel": [
"/nifti/i"
]
},
"Labels": {
"tag": "label",
"SeriesDescription": [
"Segment%"
],
"ResourceFormat": [
"NIFTI"
],
"ResourceContent": [
"/Segmentat.{3}/i"
],
"ResourceLabel": [
"/nifti/i"
]
}
}The TaggedResourceMap lets you specify resource tags ("image" and "label" here, but you can do whatever you want with them, so foo and bar are totally valid as well) and associates each tag with some criteria. Each criteria corresponds to a query that will examine one or more columns of data in XNAT's PostgreSQL database.
- SeriesDescription actually looks at the xnat_imagescandata properties type, series_description, and series_class
- ResourceLabel looks at xnat_abstractresource.label
- ResourceContent looks at xnat_resource.content
- ResourceFormat looks at xnat_resource.format
The values to search have the search operator encoded in them:
- A plain string is searched as =, so
“NIFTI”results in query criteria like resource.format = ‘NIFTI’ - A string with ‘%’ in it is treated as a LIKE, so
“T1%”results in query criteria like scan.type LIKE ‘T1%’ - Starting and ending with ‘/’ is treated as a regular expression, so
“/T1./”results in query criteria like resource.content ~ ‘T1.’ - Starting with ‘/’ and ending with ‘/i’ is treated as a case-insensitive regular expression, so
“/nifti/i”results in query criteria like abstract.label ~* 'nifti'
Resolving the Dataset
If you had a single MR session with a scan labeled "T1w" that had been converted to NIFTI format, and that scan also had a NIFTI-formatted "Segmentation" resource, resolving this definition against your session data would give you a result like this:
[
{
"image": "/data/xnat/archive/AbdomenCT-RSNA2019/arc001/48/SCANS/1/NIFTI/input_IMAGES_20191025163500_1.nii",
"label": "/data/xnat/archive/AbdomenCT-RSNA2019/arc001/48/SCANS/2/NIFTI/input_LABELS_20191025164823_2.nii"
}
]Resolved datasets return file paths relative to your XNAT's file archive root.